Architecting Shopify for High-Volume B2B: A Systems Engineering Approach
Why large-scale wholesale commerce turns Shopify into a distributed systems problem.
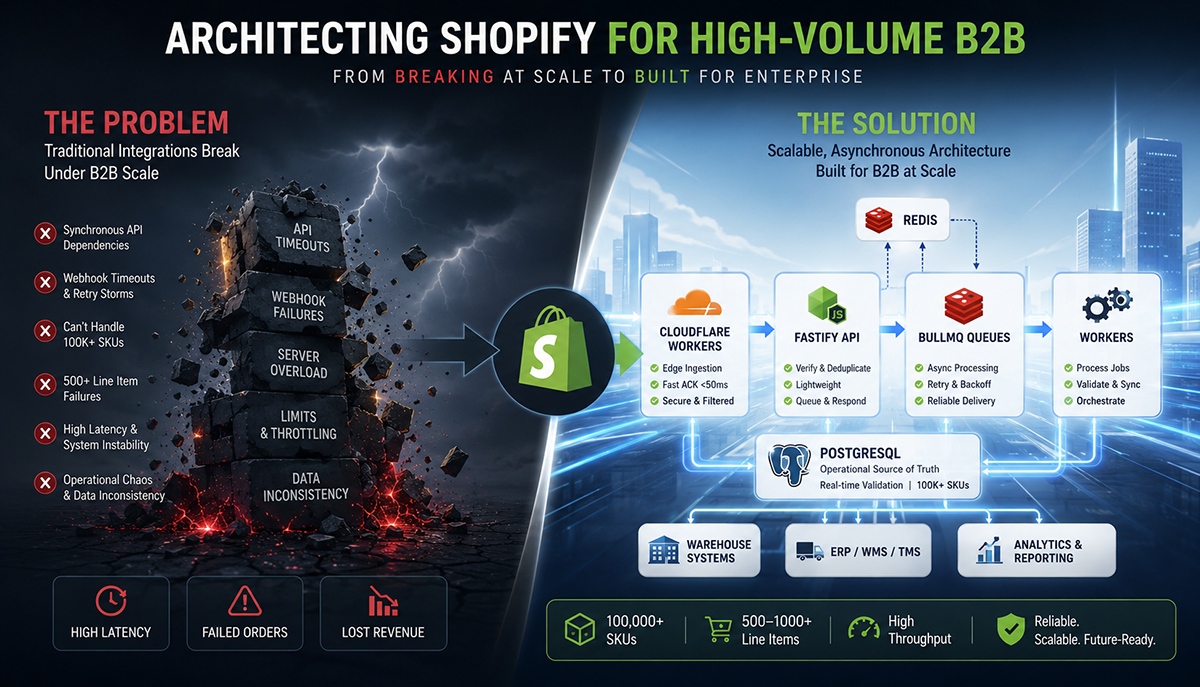
Modern B2B commerce on Shopify is no longer a simple storefront problem. Once order sizes cross 500 to 1,000 line items, SKU catalogs exceed 100,000 products, and validation rules depend on customer history, warehouse allocation, and negotiated pricing matrices, the platform stops behaving like a traditional eCommerce setup. It becomes a distributed systems problem.
This is the exact environment I designed this architecture for.
Instead of treating Shopify as the “operational brain” of the business, I completely repositioned it. In this system, Shopify is strictly the commerce interface. A dedicated Node.js and PostgreSQL backend serves as the source of operational truth for validation, orchestration, synchronization, and workflow automation.
Here is a technical breakdown of how I engineered this architecture to handle enterprise-scale B2B workloads where traditional Shopify integrations typically fail.
Why Traditional Shopify App Architectures Fail in B2B
Most Shopify integrations are built on standard Direct-to-Consumer (D2C) assumptions: small carts, low webhook throughput, lightweight validations, minimal order orchestration, and limited SKU catalogs.
B2B breaks all of those assumptions. In wholesale commerce, I routinely have to account for:
- 500–1,000 SKU orders
- Region-based warehouse routing
- Customer-specific pricing matrices
- Strict allocation restrictions and quota validation
- Complex draft-order workflows and asynchronous approvals
- Massive historical order datasets
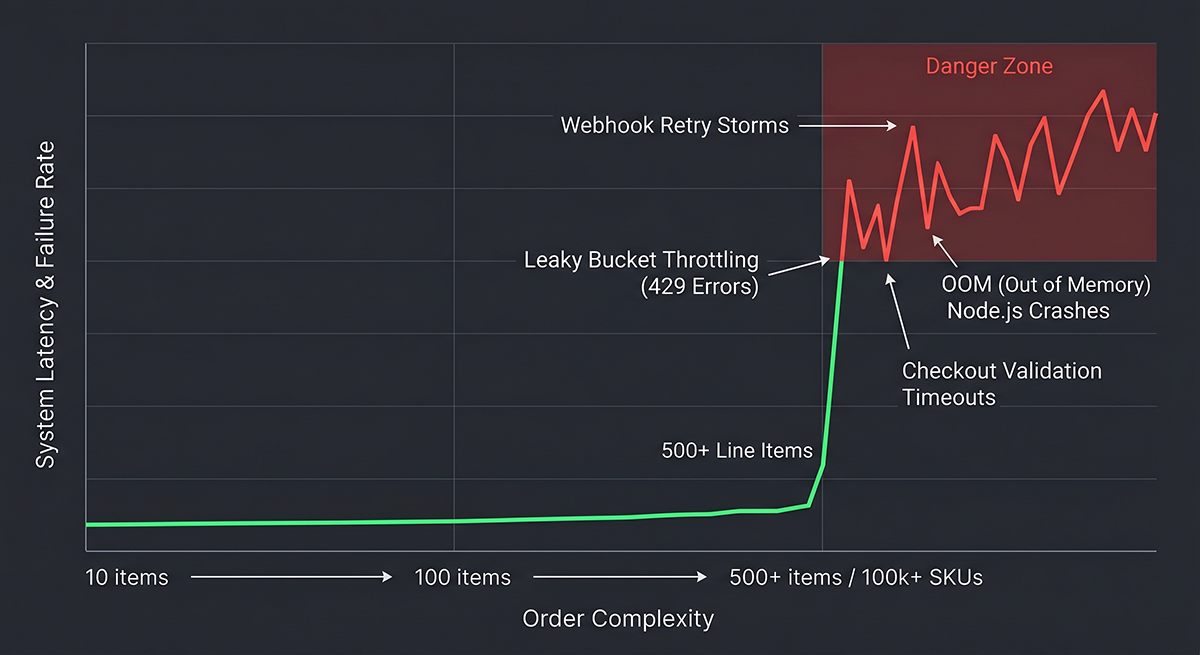
At this scale, synchronous dependency on the Shopify API becomes a massive reliability bottleneck.
The biggest architectural mistake in enterprise Shopify B2B systems is treating Shopify as the operational source of truth during real-time validation flows.
The critical architectural mistake I see most development teams make is querying Shopify in real-time during checkout validation or order orchestration. That approach guarantees cascading latency, webhook retries, API throttling, and eventual operational instability.
I built this architecture to avoid that entirely.
The Core Architectural Philosophy
To scale predictably under high-volume B2B traffic, I intentionally separated the platform into three independent layers:
| Layer | Responsibility |
|---|---|
| Shopify | The Commerce Interface |
| PostgreSQL | The Operational Brain |
| Node.js Worker System | The Workflow Engine |
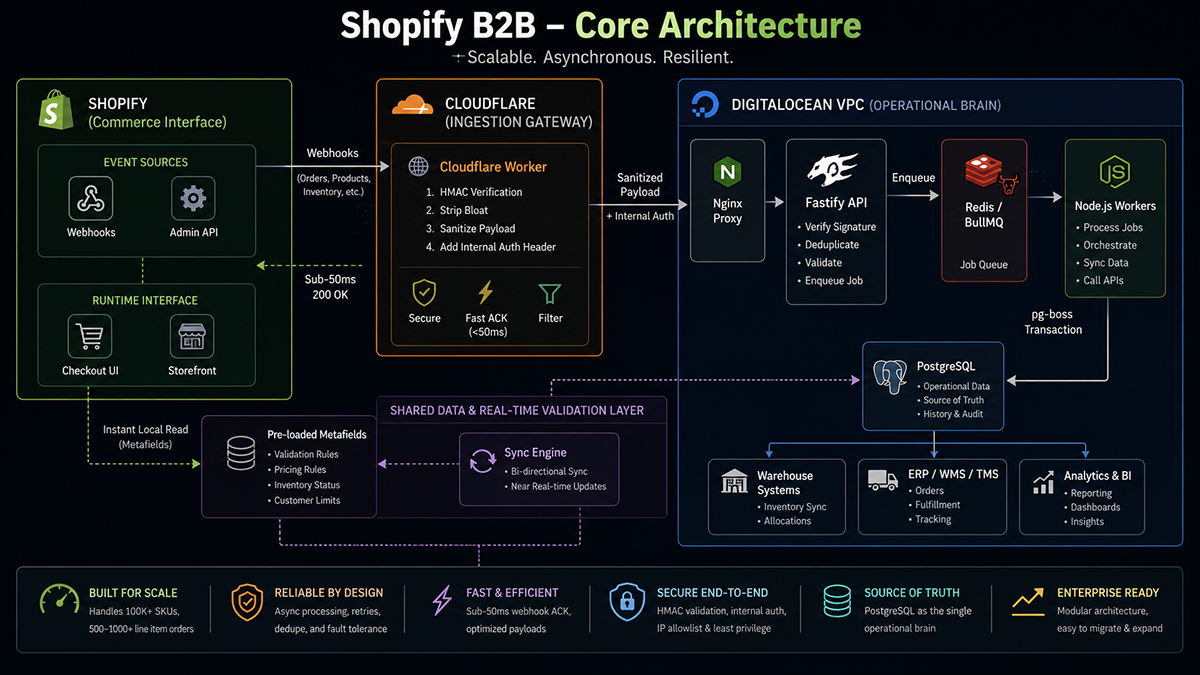
I specifically engineered this flow to solve five critical B2B scaling problems:
- Shopify webhook timeout failures and retry cascades.
- Duplicate webhook delivery and data corruption.
- Massive SKU synchronization (without memory crashes).
- High-volume draft order orchestration.
- Real-time cart validation without Shopify API dependency.
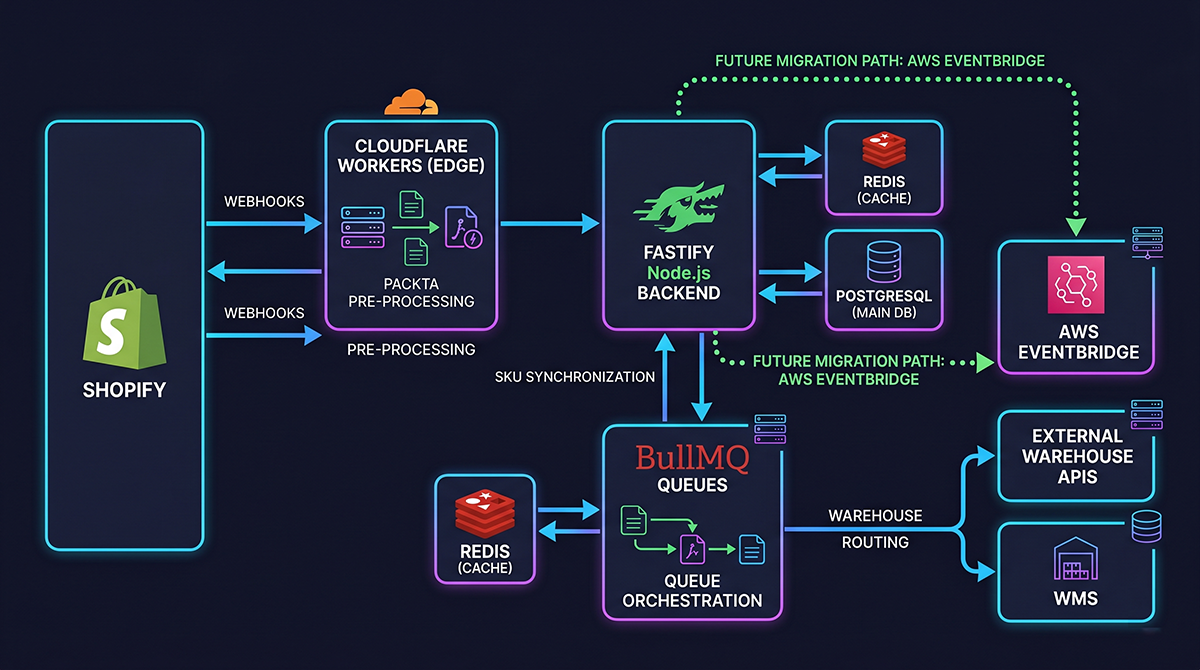
The Edge Ingestion Layer: Cloudflare Workers
One of the most important architectural decisions I made was introducing Cloudflare Workers between Shopify and my origin infrastructure.
Instead of exposing my DigitalOcean VPS directly to Shopify’s webhook bursts, the edge layer acts as a high-speed ingestion gateway. Its responsibilities include HMAC validation, request filtering, payload sanitization, metadata logging, and injecting internal authentication.
This provides three massive operational advantages:
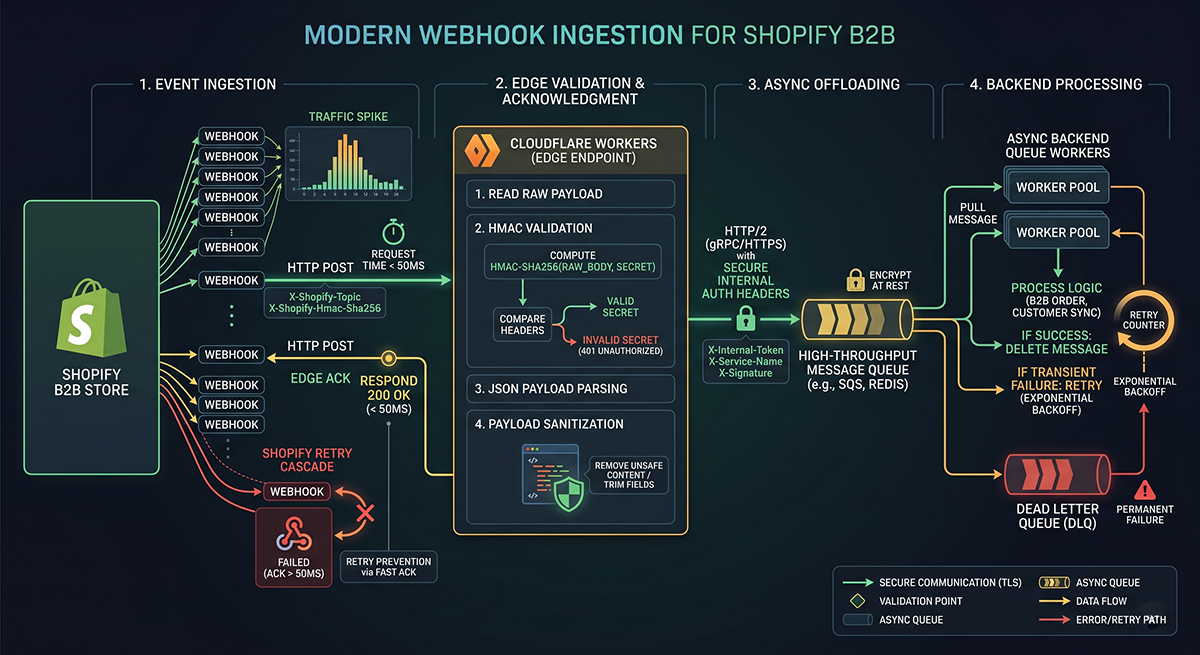
1. Preventing Shopify Retry Cascades
Shopify requires webhook endpoints to acknowledge requests within roughly five seconds. Failure triggers exponential retries. In high-volume systems, retries are catastrophic because duplicated traffic compounds backend load. My Cloudflare Worker absorbs this pressure. By utilizing event.waitUntil(), the worker provides sub-50ms webhook acknowledgment back to Shopify before the heavier backend workflow even begins. This guarantees stable ingestion during massive traffic spikes.
Shopify webhook retries are multiplicative under load. Fast acknowledgment matters more than fast processing.
2. Protecting the Origin Infrastructure
My VPS origin is never directly exposed to the public internet. Only Cloudflare can communicate with the backend via IP allowlists, VPC restrictions, and an injected internal header (X-Internal-Auth: secret-token). The backend validates both the Shopify HMAC and this internal secret, creating a hardened, zero-trust security model.
3. Payload Reduction
Shopify webhook payloads are notoriously verbose. The edge worker strips all unnecessary metadata, forwarding only operationally relevant fields. This dramatically reduces payload size, parsing overhead, memory pressure, and CPU utilization—which is critical when processing 500+ line-item B2B orders.
The Fastify API and BullMQ Queue Architecture
The backend API layer (Node.js 22 LTS, Fastify) is intentionally lightweight. It performs exactly four responsibilities: webhook reception, HMAC verification, deduplication, and queue insertion. No heavy processing happens during webhook ingestion. The route verifies the payload, adds the job to a Redis-backed BullMQ queue, and returns a 200 OK. Everything else is asynchronous.
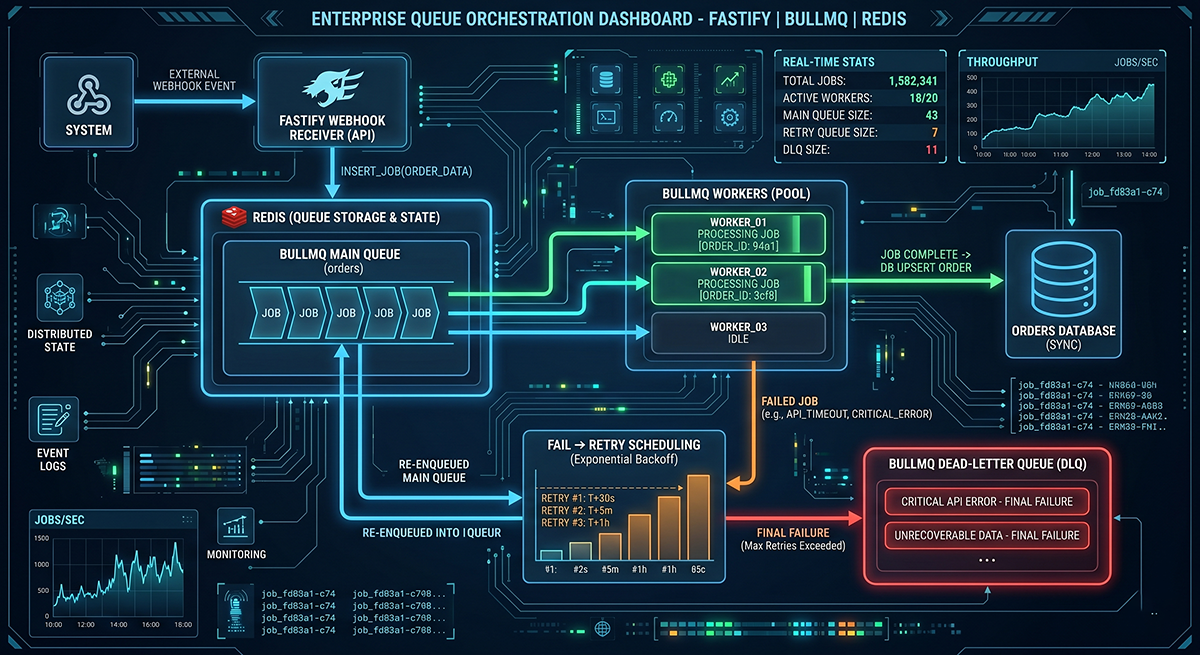
Webhook systems are inherently unreliable; they retry, duplicate, timeout, and arrive out of order. By decoupling ingestion from processing via BullMQ, temporary database hiccups never impact Shopify webhook acknowledgments. The worker system handles execution with exponential backoff, retry strategies, and dead-letter queues to prevent silent failures.
To handle the inevitable duplicate webhooks, every payload includes an X-Shopify-Webhook-Id. I store these processed IDs using PostgreSQL unique constraints. Duplicates are immediately discarded with a 200 OK, protecting the system from inventory corruption and fulfillment inconsistencies.
PostgreSQL as the Source of Truth & Massive SKU Handling
A major principle of this build was avoiding real-time Shopify dependency. The system never queries Shopify during validation flows. Shopify webhooks sync data to local PostgreSQL tables, and my local validation engine runs against that database. It stores orders, line items, quotas, warehouse routing rules, and draft-order states.
Avoiding OOM Crashes on 100,000+ SKUs
Standard approaches to syncing massive catalogs fail because loading huge Shopify JSON exports into memory causes Node.js heap exhaustion. To handle 100,000+ SKUs, I built streaming ingestion pipelines:
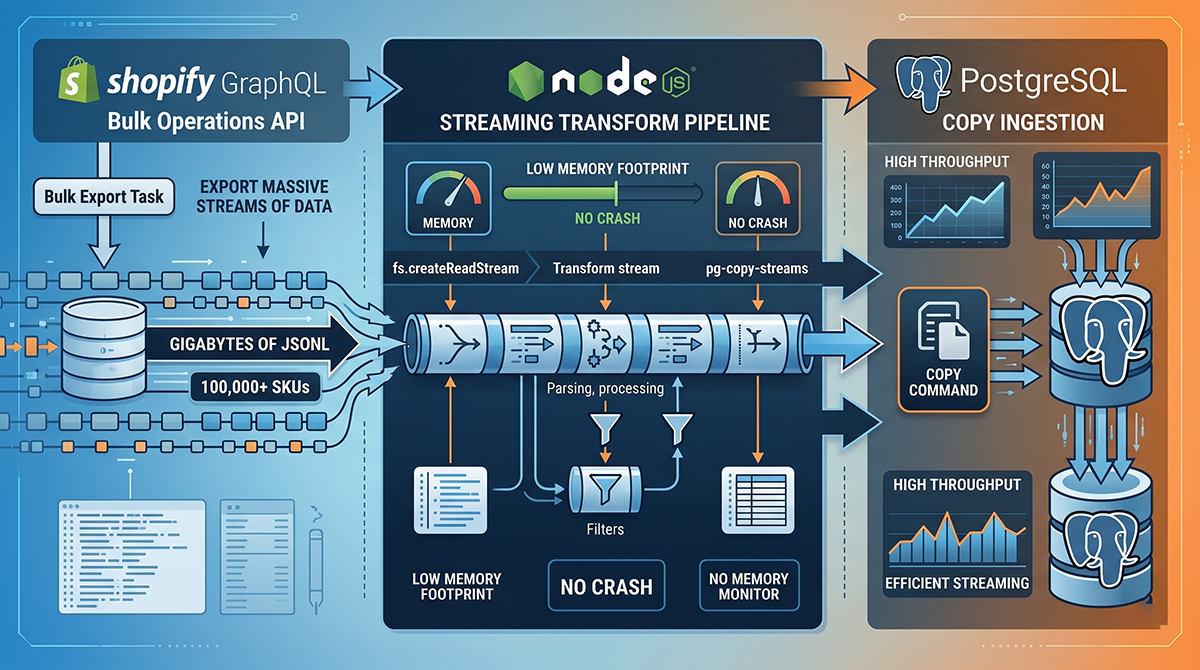
- Trigger Shopify’s GraphQL Bulk Operations API.
- Receive the massive JSONL file.
- Pipe the file through a Node.js Transform stream into
pg-copy-streams. - Execute a PostgreSQL COPY command.
By avoiding memory-heavy operations like fs.readFileSync(), this pipeline enables multi-gigabyte, crash-proof imports at maximum disk speed with minimal RAM consumption.
Loading large Shopify exports directly into memory eventually causes Node.js heap exhaustion under enterprise-scale catalogs.
Real-Time B2B Validation Engine
B2B validation logic is deeply complex. I intentionally avoided writing giant monolithic if/else logic blocks.
Instead, the validation flow is modularized (e.g., customerQuota.js, warehouseRules.js). When a cart comes in, the system runs the modular validators, collects the errors, and returns a structured response, keeping the codebase maintainable long-term.
Edge-Native Checkout Validation
Calling external REST APIs during checkout introduces catastrophic availability risks. A transient latency spike on the backend means abandoned wholesale carts.
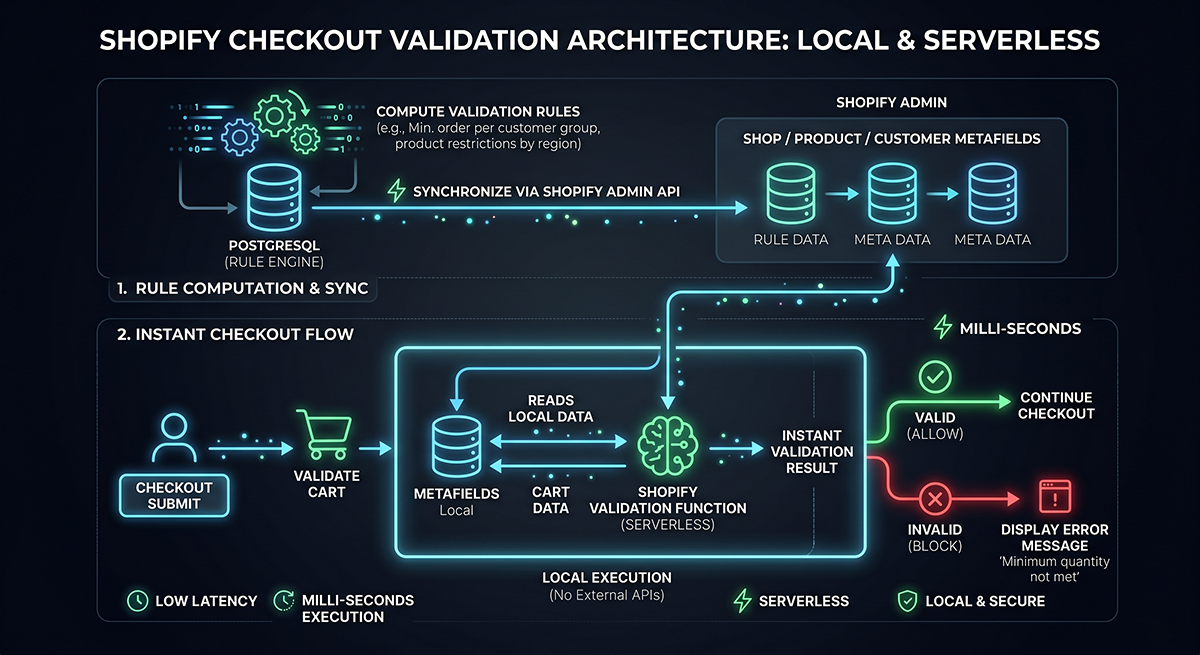
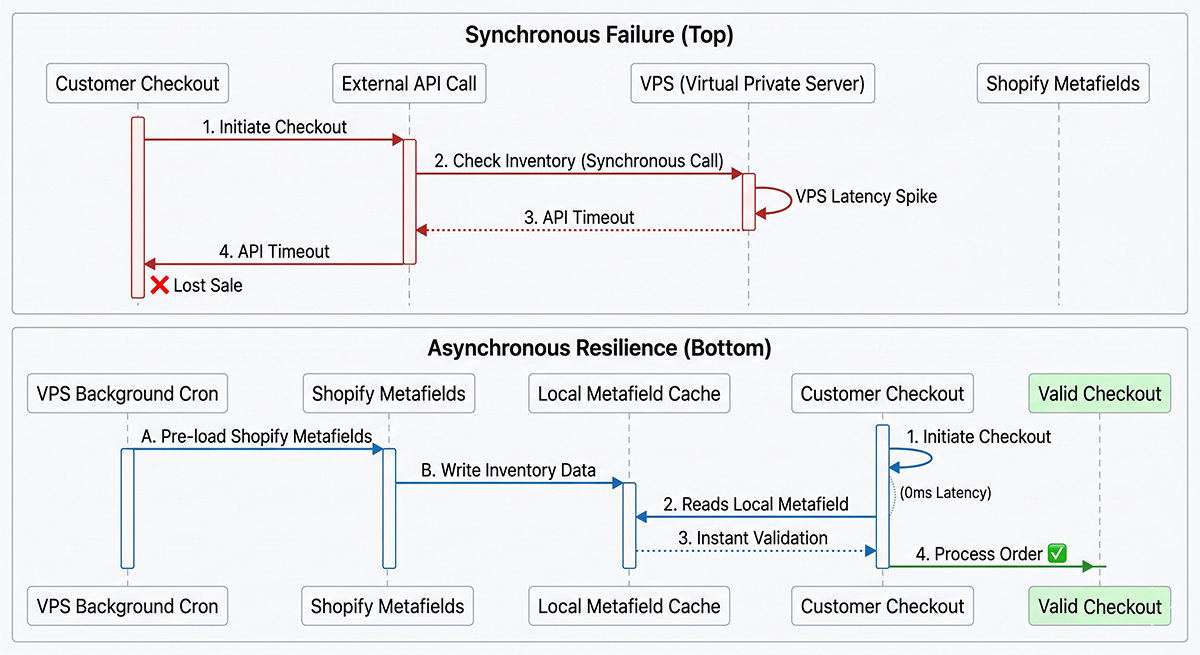
To solve this, I completely removed external HTTP requests from the checkout flow. My PostgreSQL database runs background computations to calculate validation rules, then synchronizes those constraints directly into Shopify Metafields.
At checkout, a custom Shopify Validation Function executes locally and instantly, reading the Metafields without ever hitting my servers.
Removing external API calls from checkout validation eliminates an entire category of latency-driven cart abandonment failures.
Solving Shopify’s 500 Line-Item Limit
One of the biggest B2B operational bottlenecks is Shopify’s hard line-item limit. Wholesale orders frequently exceed 500, 800, or 1000+ items.
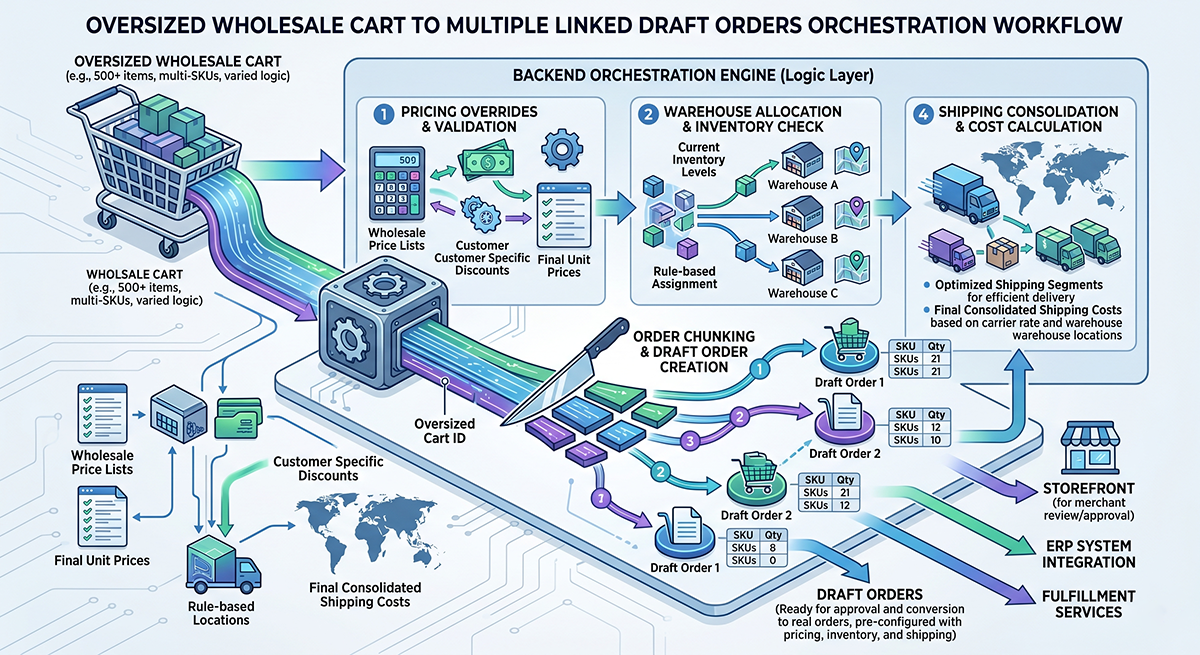
I engineered a dynamic draft-order splitting system to bypass this. When the backend detects an oversized cart (e.g., 1000 SKUs), the split engine optimally distributes the products and automatically creates multiple linked draft orders.
During this process, it applies the negotiated B2B pricing via discount overrides (FIXED_AMOUNT) and consolidates the shipping logic, completely removing operational friction for enterprise purchasing.
The Boundary Conditions: When to Use This vs. When to Pivot to AWS
Let me be clear on where this architecture shines and where it breaks down. I didn’t choose DigitalOcean and Cloudflare by accident; I chose them to solve a specific physics problem in B2B e-commerce: Egress bandwidth.
When to Stick with This Architecture
You use this Cloudflare + DigitalOcean VPC stack when your primary bottleneck is high-volume data synchronization and operational simplicity.
Synchronizing 100,000+ SKUs, downloading multi-gigabyte JSONL files from Shopify Bulk Operations, and firing heavy webhook payloads back and forth generates an immense outbound egress footprint. Hyperscalers like AWS and Azure charge roughly $0.09 per GB for egress.
If you push 10TB of catalog and order data through AWS, you are paying a massive, recurring network tax. DigitalOcean pools bandwidth (often up to 8TB included) and charges $0.01 per GB for overages.
For a small, high-performing dev team that needs raw compute power and predictable costs without wrestling with IAM roles and VPC peerings, this is the optimal path.
When to Pivot to the AWS Ecosystem
You outgrow this architecture when your requirements shift from pure e-commerce throughput to global enterprise compliance or complex event-driven microservices.
You should migrate to an AWS Serverless/Event-Driven Architecture if you hit these boundaries:
- Complex Compliance & IAM: If you are dealing with FedRAMP High, strict HIPAA requirements, or need granular, row-level access controls across a massive engineering organization, DigitalOcean’s simple security model isn’t enough.
- Global Active-Active Deployments: If you need a true multi-region database mesh with sub-millisecond global DNS failover, you need the AWS global backbone (Route53, Aurora Global).
- Hyper-Scale Analytics: If your B2B reporting requires massive OLAP data warehousing, you pivot to AWS Redshift.
Mapping This Stack to AWS:
If you do make that pivot, here is how you translate this exact logical architecture into the AWS ecosystem:
- Cloudflare Workers → Amazon API Gateway + AWS Lambda. You drop the Cloudflare edge and instead ingest webhooks via API Gateway, using a lightweight Lambda function to verify the HMAC and strip the payload.
- Fastify API & BullMQ → AWS EventBridge + Amazon SQS. Instead of managing a Node.js queue in Redis, your ingestion Lambda fires the validated payload directly onto an Amazon EventBridge event bus. EventBridge routes the event to an SQS message queue, which triggers downstream worker Lambdas to process the order asynchronously.
- PostgreSQL pg-boss (Cron) → AWS Step Functions / EventBridge Scheduler. The transactional outbox pattern we built in Postgres is replaced by Step Functions orchestrating the draft-order sync workflows and retries natively.
Final Outcome
This architecture isn’t just about “integrating” with Shopify; it transforms Shopify from a basic transactional storefront into a highly scalable enterprise B2B platform.
By taking this systems-engineering approach, I built an infrastructure capable of handling thousands of webhook events per minute, effortlessly processing 1,000-line-item wholesale orders, and synchronizing massive catalogs without memory crashes.
It scales entirely independently from Shopify’s API bottlenecks, remaining fast, resilient, and operationally predictable under the heaviest enterprise workloads.